源码解读的方式
Dapr 源码数量不少,为了有效的阅读和分工合作,我们需要建立一个可行的工作方式。
Dapr代码的背景
Dapr 代码的层次结构相对复杂,有多个维度。
按照构建块垂直划分
Dapr 的功能以构建块的方式天然垂直化为为多个功能模块,每个模块之间相对独立:
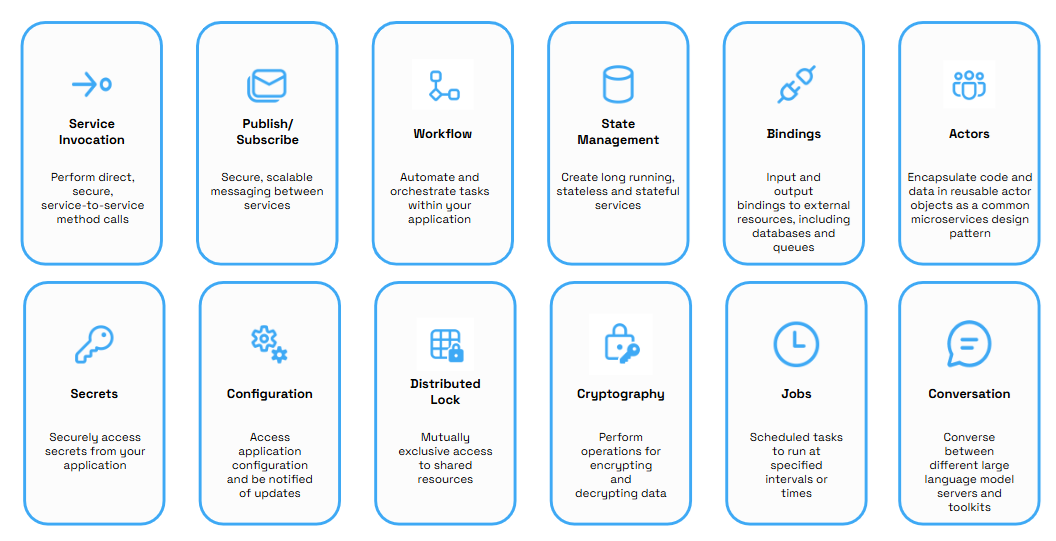
因此在代码解析时按照构建块垂直划分是一个很自然的方式。
按照分层模型水平划分
而 Dapr 在实现上,代码是按照 SDK / API / Runtime / Component 的方式进行分层的:
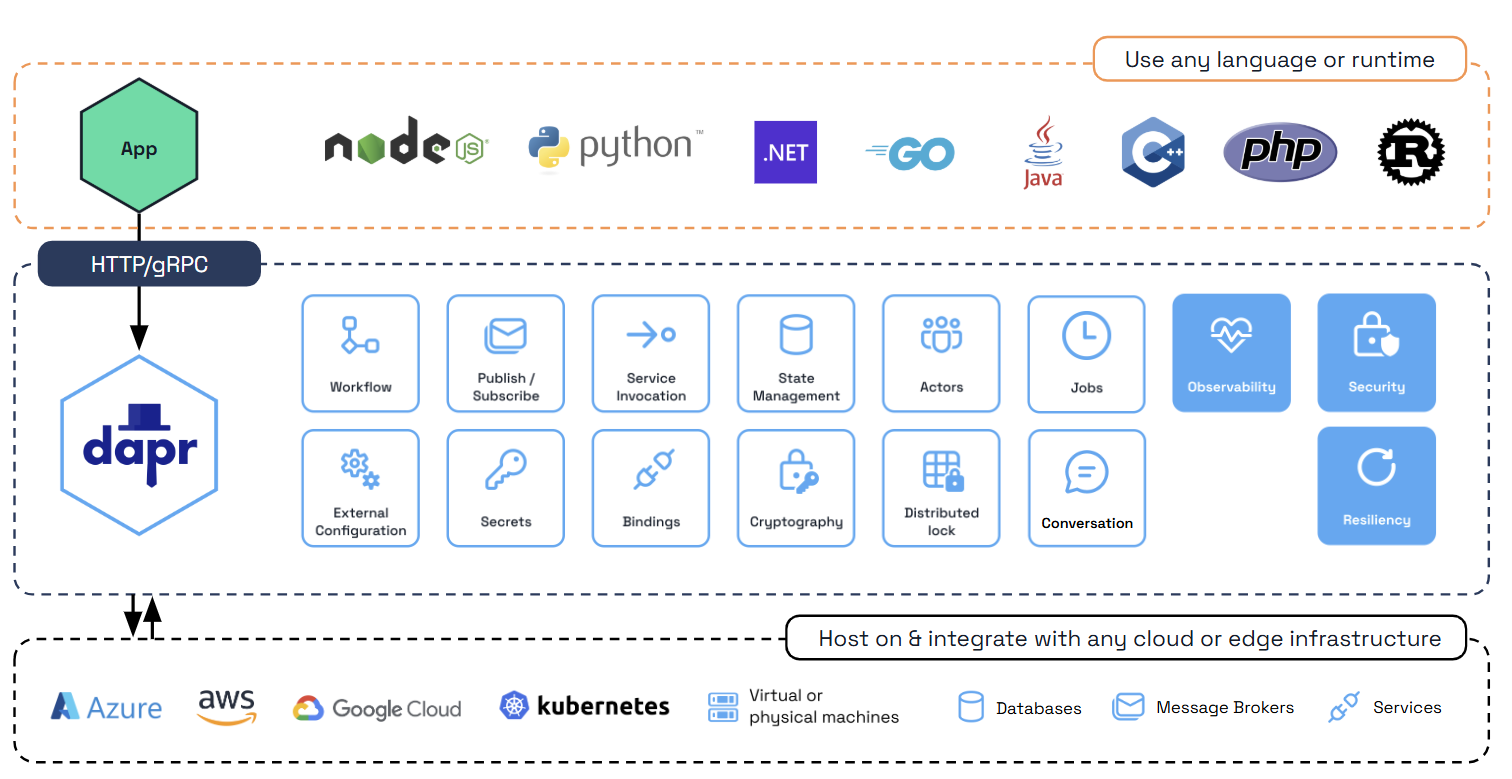
在实现层面上,每个构建块都有 SDK / API / Runtime / Component 的分层设计,而这些 SDK / API / Runtime / Component 在实现时都大量重用代码,因此我们不能简单的按照构建块先做垂直划分,然后再按照 SDK / API / Runtime / Component 的分层设计做水平划分,这样会有大量的重复。
SDK 有多语言实现的差异
单独看 SDK,每个 SDK 在功能实现上按照构建块垂直划分,但由于 SDK 主要是完成和 sidecar 的请求交互,因此排除 API 参数的细节之外,在实现层面上其实每个构建块的实现差异并不大。
而不同语言的 SDK 之间,有部分内容是基本一致的:对 dapr API 请求的实现,包括参数的具体处理。但在具体实现层面上,不同语言的实现方式差异可能非常大。
此外不同语言 SDK 对 API 的支持程度不同,尤其是细节的特性方面并不完全对齐。
因此在 SDK 代码阅读时,需要将通用的内容和 SDK 特有的内容区分开。
Component实现中的代码重用
Dapr 早期代码实现中,每个 component 的代码都是独立的。但这就造成了一个问题:如果可以支持多个 dapr 的构建块,就会出现多个 component,如下图中的 redis:
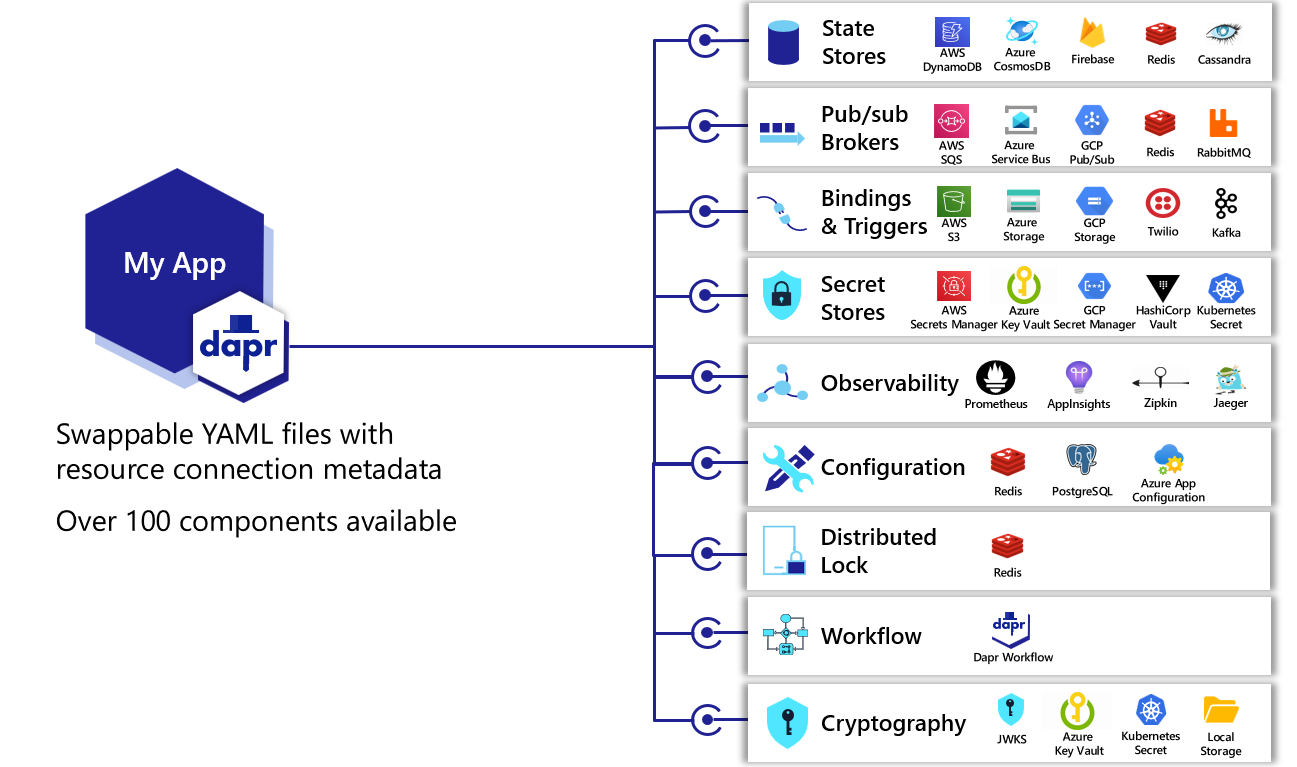
这会导致大量的代码重复,尤其是连接/认证等基本功能几乎每个组件都是要重复一次的。
目前 redis 和 kafka 进行了代码重构,提取了公用代码,然后基于这些公用代码再实现不同的 component。
但部分 component 还没有重构,存在代码重复问题。
我们做代码解析时就需要考虑这些组建中的重复代码:需要识别重复代码,并小心识别这些重复代码中有差异的地方(copy-paste-modify)。
runtime公用代码
dapr runtime 中有部分代码是公用的,
- 日志
- 监控
- 配置的装载:standalone下读取文件夹,k8s下读取CRD
但有部分代码又和构建块有部分联系,典型如:
- runtime 的启动/停止
- component 的装载,初始化和关闭
- 命令行参数、环境变量的获取
控制平面的代码
控制平面中,不同模块和构建块的关系是完全不同的:
-
placement:和 actor 构建块直接关联的,可以视为是 actor 构建块划分的范围内。可以在 self-hosted 和 kubernetes 模式下使用。
-
sidecar injector :完全独立于所有的构建块之外,仅在 kubernetes 模式下使用
-
operator:仅在 kubernetes 模式下使用,服务于所有的组件。
-
Sentry: 负责生成和发送 mTLS 证书,可以在 self-hosted 和 kubernetes 模式下使用。而加密通许可以用于sidecar之间的通讯,也可以用于sidecar和component,以及sidecar和控制平面之间的通讯。
测试代码
Dapr 中有不少测试代码,如 unit test, e2e test,performance test,certification test。这些代码中 e2e test,performance test,certification test 都是有各自的体系的,尤其 e2e test,performance test 涉及到测试环境的搭建和测试应用的部署,有一套完整的设计和实现。
这些代码对于深度了解 dapr,尤其是重度参与 dapr 开发非常重要。
源码解读方式
个人的经历和心得
我(敖小剑)曾在自己的 dapr 学习笔记中尝试做一些源码的阅读工作,早期是将各种内容存放在一起的,后来发现有个很大的问题,就是各种内容堆在一起之后太过嘈杂:high level的原理、架构、设计、流程,和细节的代码实现绞在一起。宏观的知识点和微观的细节无法得到合理的组织,写起来乱,看起来也乱。
因此,我希望在这次的源码解析活动中,放弃简单的罗列内容和代码,重新尝试按照不同的阶段和层面来进行源码解读:
- 流程:包括主流程和分支流程(一般是某个高级特性),只关注宏观信息,尽量不涉及细节
- 细节:源码实现的具体方式,专注于小范围内的细节,强调深度
- 设计:在代码之外的内容,帮助更好的理解代码的架构和设计,以及产品相关的理念,技术背景等
下面是我建议的源码阅读活动的方式(草稿),作为我们讨论开始的输入,后续根据讨论情况和实际执行情况不断调整和更新。
梳理 Dapr 流程
按照构建块和特性整理 Dapr 的功能点,梳理 Dapr 请求处理流程,学习了解 Dapr 功能实现的整体情况。
原则上说,在这个层面上,我们的阅读目标是对 dapr 的功能点和整体的流程有个 high level 的了解,然后将这些信息汇总起来,一方面可以帮助我们全面的了解 dapr,另一方面可以作为下一步深入代码细节的输入。
这个环节在操作中最重要的点是:
- 不要疏漏:这是下一步的输入
- 不要深入细节:这是下一步的内容
这个环节的产出物:
-
流程分析:包括主流程和分支流程
参考:https://skyao.io/learning-dapr/sources/service-invoke/main-process/overview.html
-
流程中涉及到的关键功能点:这是下一步要深入的细节
产出物应该是一个功能列表,也可以是 mindmap 的形式,通过链接可以访问到对应的实现细节。
深入 Dapr 细节
通过深入阅读源码全面而细致的了解 Dapr 的代码实现,掌握 Dapr 的处理细节,从点到面,覆盖所有的知识点。
这个部分才是大家熟悉的阅读源码的环节,真正的深入代码细节,在上面梳理流程得到产出物之后,再有针对性的就某个功能进行深度展开。
这个环节可以理解为解读一个一个类似的问题:某某功能是如何实现的?
产出物:
- 某细节功能的详细源码实现分析
- 涉及到的技术实现细节
尽量不要展开其他内容:
- 流程性的内容在上一个环节,可以引用或者链接
- 架构/设计/原理/产品分析等在下一个环节,可以引用或者链接
归纳 Dapr 设计
在掌握流程和细节的基础上,归纳总结 Dapr 的架构和设计。结合业务场景和业界实践,探讨 Dapr 的产品思路,理解 Dapr 的设计方案。
解读源码实现时,必然会涉及有相关的背景知识,有些是技术相关,比如安全通讯时需要了解什么是 mTLS,分析 actor 代码时需要了解 actor 并发模型,pub/sub模型中使用到 cloudevents 规范,可观测性支持 open telemetry 规范等。这些内容尽量不在流程和细节这两个环境详细展开,而是单独放出来。
读者可以选择看或者不看,也可以选择在看源码解析前看或者看完源码解析后看。
另外会有一些和产品设计和理念相关的内容,这些内容和 dapr 源码实现的关系会比较远,比如分布式状态业界有一个 cloudevents 项目可以参考,spring cloud stream 项目也做了和 dapr pub/sub 类似的抽象和可替换实现,actor 产品从 orlands 到 dapr actor 的演化。
这些内容可以帮助我们更好的理解 dapr 源码背后的产品思路、技术理念、实现演进,也能极大的拓展知识面。
Action
步骤1: 流程列表和功能列表
- 快速摸清dapr的主流程和功能点
- 产出流程列表和功能列表:mindmap
步骤2: 分工
使用 github 的 project 功能
https://github.com/dapr-cn/dapr-cn-site-source
就上述流程列表和功能列表中的内容进行分工
步骤3: 分工阅读
内容提交在 https://github.com/dapr-cn/dapr-cn-site-source 中
大家可能需要稍微了解一下 hugo 的基本使用。